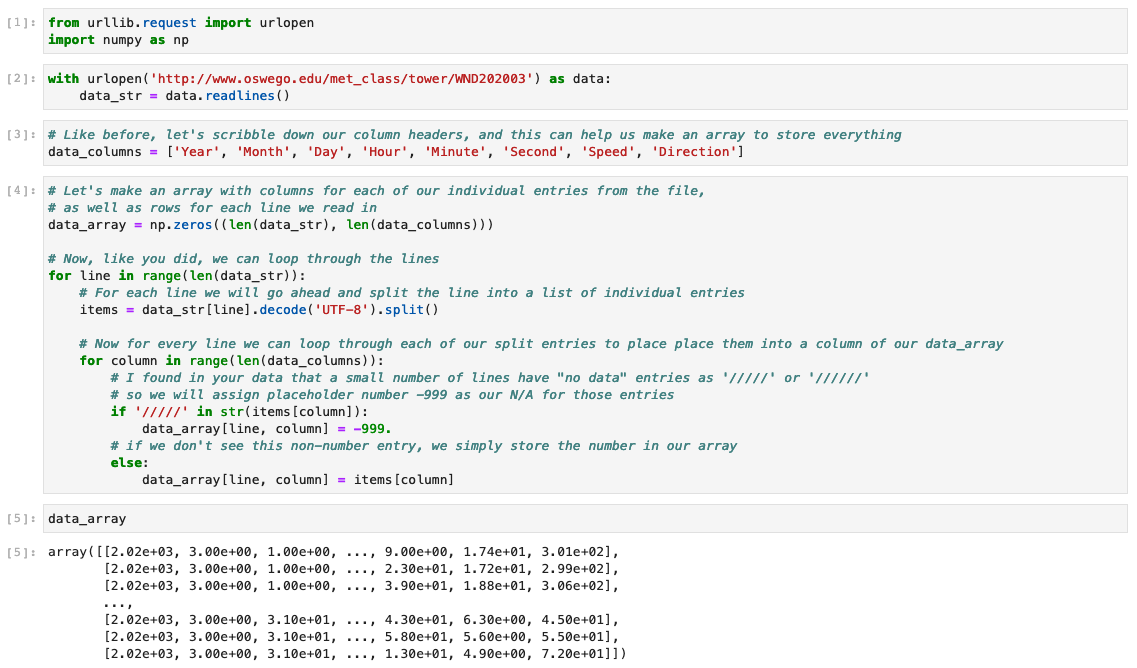
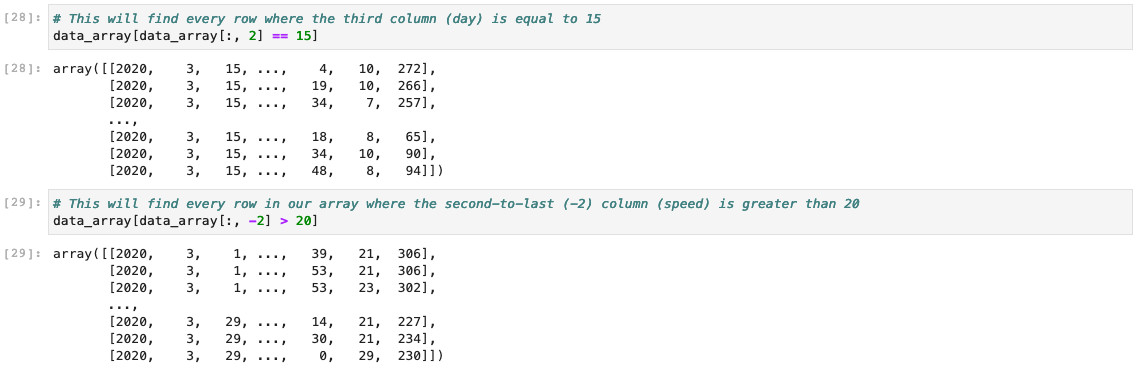
Hello, and thanks for reaching out for help! I am unable to recreate your issue with Pandas, but try adding "encoding='utf8'" as below df = pd.read_fwf(data, names=data_columns, encoding='utf8') If this doesn't work, make sure your installation of Pandas is up-to-date. If this is the case and you still have this issue, please let me know what version of Python you're using and verify what version of Pandas you have installed and I will try to recreate the issue. If you are able to read in your data as a Pandas dataframe, this is a good opportunity to read up on some of the super powerful ways Pandas can help you sort through your data: https://pandas.pydata.org/docs/getting_started/intro_tutorials/03_subset_data.html#min-tut-03-subset Still, we can also do things by hand! So as for the second piece of code, the only issue is that you've separated out a nested loop. This was actually a loop within a loop, and if you split them between Jupyter cells they will no longer function together. The loops I provided will loop through every line of the file, and then within each line loop through every column to find missing data. So, your cells should look like the first attached screenshot. In your case you only looped through the columns of one line, and so you only saved that one line. If you'd like to then take your data array and pull out lines that meet your certain criteria (say, data from certain days/hours, or data points with speeds over 15, etc.), then we can still do that by hand as well. You can use conditional statements to help you subset numpy arrays. This can take some practice and some internet sleuthing, but it can be incredibly powerful. The second screenshot has a few quick demonstrations of what you can do, but I recommend starting with the numpy documentation (https://numpy.org/doc/stable/user/basics.indexing.html) and seeking out other guides for doing this by hand for more in-depth information! I hope this helps, and if I can help any further don't hesitate to reach out. Thank you! All the best, Drew > I am emailing python support because I > received some valuable code for a project I was working on when I emailed > this service ([python #HGQ-627384]: Python Coding Inquiry) earlier but I > ran into some problems when trying to use the code in Jupyter Notebook. The > code I received was: > > from urllib.request import urlopen > import numpy as np > import pandas as pd > > # Since you know what data you're looking at here, let's go ahead and > specify the names we want the columns to have > data_columns = ['Year', 'Month', 'Day', 'Hour', 'Minute', 'Second', > 'Speed', 'Direction'] > > with urlopen('http://www.oswego.edu/met_class/tower/WND202003') as data: > # We will use the Pandas read_fwf to read in our fixed-width data > from this page into a Dataframe > df = pd.read_fwf(data, names=data_columns) > > > The error I received when I used the code is on image py.PNG attached below. > > The second code I received from python support is: > > from urllib.request import urlopen > import numpy as np > > with urlopen('http://www.oswego.edu/met_class/tower/WND202003') as data: > data_str = data.readlines() > > # Like before, let's scribble down our column headers, and this can help > us make an array to store everything > data_columns = ['Year', 'Month', 'Day', 'Hour', 'Minute', 'Second', > 'Speed', 'Direction'] > > # Let's make an array with columns for each of our individual entries > from the file, > # as well as rows for each line we read in > data_array = np.zeros((len(data_str), len(data_columns))) > > # Now, like you did, we can loop through the lines > for line in range(len(data_str)): > # For each line we will go ahead and split the line into a list of > individually decoded entries > items = data_str[line].decode('UTF-8').split() > > # Now for every line we can loop through each of our split entries to > place place them into a column of our data_array > for column in range(len(data_columns)): > # I found in your data that a small number of lines have "no > data" entries as '/////' or '//////' > # so we will assign placeholder number -999 as our N/A for those > entries > if '/////' in str(items[column]): > data_array[line, column] = -999. > # if we don't see this non-number entry, we simply store the > read-in number in our array > else: > data_array[line, column] = items[column] > > > > With this code, I get an array of zeros with only one line being read at > the very end of my data set which is provided on the py2.PNG image attached > below. The main goal of my code was to 1- read lines of data on a website, > 2-have the code find a line with specific numbers of my choice, and 3-print > out that specific line of data. Is there an extra line of code or something > that I missed which is why it's not working for me in Jupyter Notebook? > Thank you! > > Ticket Details =================== Ticket ID: HGQ-627384 Department: Support Python Priority: Low Status: Closed =================== NOTE: All email exchanges with Unidata User Support are recorded in the Unidata inquiry tracking system and then made publicly available through the web. If you do not want to have your interactions made available in this way, you must let us know in each email you send to us.
Attachment:
Screen Shot 2020-04-23 at 11.43.57 AM.png
Description: PNG image
Attachment:
Screen Shot 2020-04-23 at 11.39.43 AM.png
Description: PNG image
{kind=link}
{kind=link}