Web site upgrade to version 3.0
The Unidata web site is in the process of being 'upgraded' for improvement. The new website, which will be deployed late spring/early summer 2008, will see changes in four following areas:
Spring is here
In early March, John Caron and I attended a four-day training course on the basics of the Spring Framework. Spring is widely used for J2EE web development by the rest of the planet (it seems we are among the few who are not currently using it). The THREDDS group and I figured it would be a good time for Unidata to see what the hype is about.
Unidata developer's blog
An interesting conversation with John Caron has resulted in Jen installing blogging software on the Unidata website.
Changes to McIDAS ACRs
Some recent changes have been made to the Access Control Rules that govern access to McIDAS based on some concerns about distribution of Unidata McIDAS-X to institutions outside of the United States.
RAMADDA
Jeff McWhirter has been developing a Repository for Archiving, Managing and Accessing Diverse DAta (RAMADDA). Jen and Jeff spent some time in creating a servlet wrapper so that RAMADDA could be run as web application within a servlet container (such as Tomcat) in addition to its normal standalone mode.
Mailing list and forum saga continues
Alas, the mailing list and forum saga is not over. After a year of running in production mode, the current setup is showing its strengths and weaknesses.
Why Google Analytics is cool
Jen set up an account with Google Analytics and has had it tracking the Unidata website. By registering with the Google Analytics site and adding some JavaScript to our pages (easy with mod_layout), Unidata essentially now has a free, online website analysis package that gives us just as much information as Sawmill, AWStats, etc.
The Unidata web site is in the process of being 'upgraded' for improvement. The new website, which will be deployed late spring/early summer 2008, will see changes in four following areas:
Refactoring of the code
The code responsible for the 'dynamic' portion of our website is being refactored. A few years of use and bug fixes have highlighted the need for a change in infrastructure. Our current site is getting complex enough that the use of a custom, home grown architecture is starting to cause problems.
With a few exceptions, the Unidata website makes heavy use of JSP and Java servlets for its interactive functionality. While taking a if it isn't broken, don't fix it approach, the parts of the site that rely on JSP and Java servlets will be refactored to utilize the Spring framework. The use of Spring will allow a quick refactoring of the site structure while utilizing most the pre-existing java code as POJOs (read: keep as much of the existing code as possible to use in the new site).
The main benefits of using Spring are:
• ease of website maintenance;
• quicker turnaround time for feature requests; and
• overlap/sharing of expertise.
More information about Spring and its benefits/uses follows.
Refactoring of the database
The community user database used by the website is also in need of some structural changes. Refactoring the database will include the removal of unused table columns and consolidation of common user information in tables. This should result in more efficient queries and quicker page loading. E.g., many website pages get their content from the database. The Access Control Rules which govern access to selected Unidata website content also depend on database queries. Hence, database efficiency and continued maintenance is important.
A furture goal is to employ an object-relational mapping persistence mechanism (are we buzzword compliant yet?) such as Hibernate. Refactoring the database is needed to make the java object to relational database mapping seamless.
Unidata software downloads
The current downloads section of our site works well, but a few small changes are needed.
MD5 and other checksum support will be added to ensure integrity of the download.
Rendering of the current downloads pages utilizes XSLT through a very complicated stylesheet (a.k.a the Stylesheet of Doom) which gives Jen a headache every time she looks at it. The original idea behind using the stylesheet and XSLT was that Unidata developers could extend the XSLT functionality to create their own stylesheets to customize the download page for their particular package. As of yet, no developer has taken advantage of this feature, thus making the XSLT a bit of overkill. Therefore, the downloads mechanism for the site will be refactored to use Spring (of course) and remove the XSLT rendering of the developer-provided XML content. (Developers generate xml files, often during their build process, that is rendered for the user to access and download their packages). Neither developers nor website users will notice a change to how download information is rendered.
Some important changes have been made to the Access Control Rules that govern the access to the McIDAS downloads. Please see below for more information about this.
Omnipresent diligence in the use of PHP
The use of PHP has all but been eradicated from the Unidata website. Certain measures are being taken to confine the remaining PHP application to a smaller sandbox. As this status report is public, I'm not going to go into details, but if you are really curious as to what these 'measures' are, contact Jen.
Making the life of Unidata staff easier
Using Spring will make it more feasible to add 'hooks' into the underpinnings of the website. Having access to the underpinnings of the site can make it easier for the staff to access/change website data that is currently out-of-reach. (Currently, the staff consults Jen or Tina to gather certain types of information or make changes to selected content on the website.)
Website and user information and statistics will become more accessible for report gathering, metrics, assessment, etc. Also, making changes to specific content will be easier without any danger of modifying site-wide CSS, etc., (WYSIWIG to the rescue).
Jen is soliciting staff input on website features they would like to see changed. Suggested improvements will try to be accommodated in the upcoming release of the website.
The code that handles user registration is being refactored. The following changes are being implemented (listed in no particular order):
- [security fix] Change web site registration confirmation from being strictly email-based to a combination of email- and web-based.
- [bug fix] The user can request his/her password to be reset in addition to setting a password reminder.
- [security fix] Transition password to use more restrictive set of chars to coincide with the Unidata authentication XSS prevention mechanism.
- [new feature] Provide interactive form help, tips, and validation using AJAX and CSS.
- [new feature] Use a postal code database to automatically lookup other geographic location information (thus saving the user from having to provide this information). Postal code information is provided free from the US Postal Service.
- [security fix] Implement a lockout for numerous consecutive failed login attempts (with email notification to Jen so that she may identify and help legitimate users who need assistance).
- [new feature] Highlight and provided necessary info for required form fields for GEMPAK & McIDAS access/support during registration process.
- [security fix] Improve the Site Help section to include basic troubleshooting tips, such as what to do if the user did not receive a registration confirmation email in a timely manner.
The code that handles website user account information is being refactored. The following changes are being implemented (listed in no particular order):
- [new feature] Allows a user to specify more than one email address for their account. (The email address is the way to uniquely identify users. This will allow a user to securely link/identify other accounts as belonging to one person. This is particularly helpful when dealing with mailing list membership.)
- [new feature] Display the user's email list subscription information, as well as provide a mechanism for the user change his/her subscription options.
- [new feature] Connect the user's download history to his/her mailing list subscriptions and make suggestions if the user is not subscribed to a list he/she might find helpful.
The current Unidata web site design, while adequate, needs updating.
The PV2 group, Linda Miller, and Jo Hansen will meet on April 21th to provide feedback on the possible choices of design for the new site. Over the next couple of months, the design will be refined based on the input from the staff, User's Committee, Policy Committee, and any interested community member.
The new design addresses known usability issues and provides some new features that hopefully the community finds interesting and helpful. Making extensive use of CSS, JavaScript, and AJAX, the new design will provide a richer user experience for site visitors.
Incorporating Web2.0-ish technologies into our site provides almost limitless possibilities for Unidata to provide useful and interesting content to our users not easily accessible before.
Among the planned changes are:
- [new feature] Incorporate Google Suggest and Google Trends into Unidata site search and support pages.
- [new feature] Provide RSS feed and PDF print-friendly page support for first and second tier pages.
- [new feature] Deploy an interactive calendar of events.
- [new feature] Provide helpful 'File Not Found' pages to provide user with options to find website content (Google Trends).
- [new feature] Display a mashup showing the geographical location of software downloads and general community members using AJAX, and Google Maps.
We will hold off on the use of HTML5 until it gains more support in broswers and clients.
The use of CSS-based layout should make it easier for Unidata staff to add/modify website content without having to muck with multiple nested HTML tables. Care is being taken to make sure that users with older browsers with limited CSS and JavaScript support will still be able to access and use the major (important) functions the Unidata site (e.g., software downloads, support, etc.)
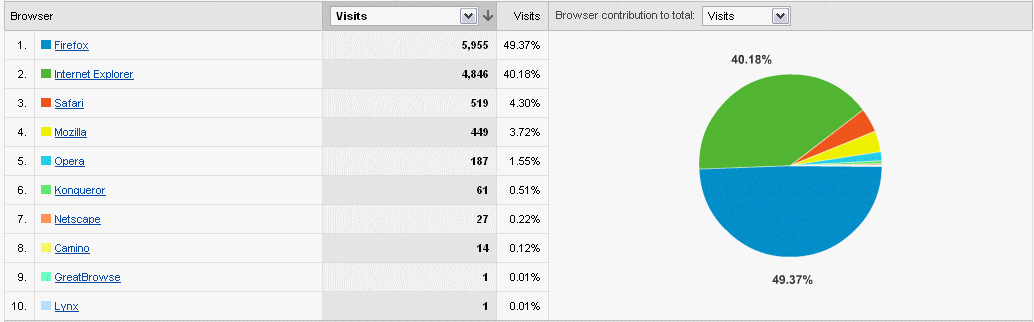
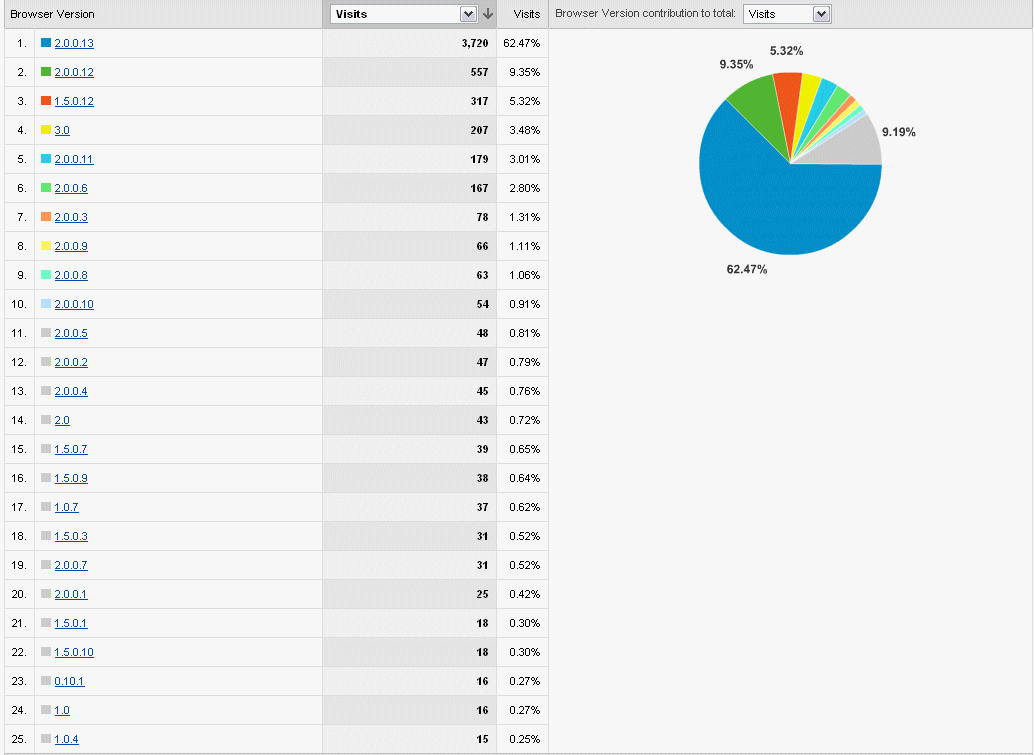
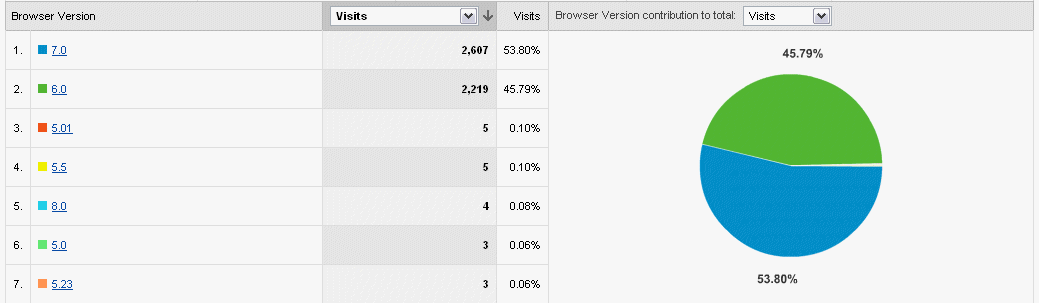
Browser stats of site visitors
Click to enlarge imageFirefox browser version stats
Click to enlarge imageIE browser version stats
Click to enlarge imageUnidata is also taking an active role in UOP to provide a website design that displays the UPC's affiliation with UOP and UCAR. (NCAR recently implemented an NCAR-wide redesign of all websites to accommodate a mandate for a common 'branding' from the NCAR President's office. While UOP has no such requirement for a common look across programs, an interest to show a common affiliation has been expressed). Jen and Tina met with Hanne Mauriello (UOP director's office), Kelly Lewis (UOP director's office), and Zhenya Gallon (UCAR Communications) to discuss such site branding. Unidata is taking a leadership role in providing a possible branding solution in the new Unidata website redesign (perhaps to be used by other programs across UOP).

In early March, John Caron and I attended a four-day training course on the basics of the Spring Framework. Spring is widely used for J2EE web development by the rest of the planet (it seems we are among the few who are not currently using it). The THREDDS group and I figured it would be a good time for Unidata to see what the hype is about.
In a buzzword-laden nutshell, Spring is a lightweight, inversion of control and aspect-oriented container framework (bla, bla, bla).
Looking past the buzzwords and hype, does Spring offer something that will make development easier/quicker? Was it worth our time and Unidata's $$$ to send us to this training? John and I think it was.
We experienced several Ah ha! moments when learning of how Spring could easily solve some complex development problems. Spring measures up to the aforementioned buzzwords in a good and practical sense:
Lightweight
This can have a couple of meanings in the Spring context:
One interpretation: Plain Old Java Objects (POJOs) in a Spring application typically have no dependencies on Spring-specific classes. Separation of duties. Your code is the meat and potatoes of the application, while small amounts of Spring is used to bind it all together.
Another interpretation: Just drop a few of small jar files in your classpath and you are ready to go. Spring has a lot of bells and whistles, but you don't necessarily have to use them. (Spring comes bundled in different sets of jar files depending on which features of Spring you want to use.) In the web world, just configure Spring to run like you would any servlet (via the deployment descriptor) and you instantly have access to the Spring framework/container.
Inversion of Control (IoC) - Dependency Injection
Do a Google search of inversion of control and the first hit you will get is an article written by Martin fowler defining the IoC pattern and giving it the more helpful term of dependency injection.
Learning about dependency injection was one of those Ah ha! moments for me. It is cool in a geeky sort of way. Using this pattern I can write modular code in the form of POJOs and POJIs (Plain Old Java Interfaces) which can be swapped out or replaced without having to touch the other POJOs that use/depend on it.
I'm not going to go into depth about IoC or dependency injection. I'll let you RTFM for yourselves (see links below). But here is a 50,000ft view of what it is:
Creating the POJOs
Example: I have a
UnidataStaffMemberobject with the following attributes/dependencies:ucar.unidata.plaza.UnidataStaffMemberpackage ucar.unidata.plaza; public class UnidataStaffMember { private String name; private WriteStatusReportTask task; public UnidataStaffMember (String name) { this.name = name; task = new WriteStatusReportTask (); } public StatusReport doTask() throws NothingToReportException { return task.perform(); } }And the
WriteStatusReportTaskmight look like this:ucar.unidata.plaza.WriteStatusReportTaskpackage ucar.unidata.plaza; public class WriteStatusReportTask { public WriteStatusReportTask(); public StatusReport perform() throws NothingToReportException { StatusReport statusReport = null; // write the status report return StatusReport; } }The
UnidataStaffMemberobject is strongly coupled with theWriteStatusReportTask. What if we want to have aUnidataStaffMemberobject that performs another type of task instead of just writing status reports?Reducing POJO coupling
To reduce this coupling,
WriteStatusReportTaskis hidden behind a more genericTaskinterface. The actual implementation of theTaskcan be swapped out without affecting theUnidataStaffMemberclass:ucar.unidata.plaza.Taskpackage ucar.unidata.plaza; public interface Task { abstract Object perform() throws TaskNotPerformedException; }And our new implementation of
WriteStatusReportTasklooks like this:ucar.unidata.plaza.WriteStatusReportTaskpackage ucar.unidata.plaza; public class WriteStatusReportTask implements Task { public WriteStatusReportTask(); public Object perform() throws TaskNotPerformedException { StatusReport statusReport = null; // write the status report return new StatusReport(); } }And our
UnidataStaffMemberclass makes use of this new interface:ucar.unidata.plaza.UnidataStaffMemberpackage ucar.unidata.plaza; public class UnidataStaffMember { private String name; private Task task; public UnidataStaffMember (String name) { this.name = name; task = new WriteStatusReportTask (); } public Object doTask() throws TaskNotPerformedException { return task.perform(); } }Getting closer, but the
UnidataStaffMemberobject will be stuck only writing status reports and not performing other types of tasks (not very productive).Also, the
UnidataStaffMemberis responsible for obtaining his/her own tasks which is not necessarily a good thing. We want community needs to dictate the assignment of tasks given to theUnidataStaffMember. Therefore:ucar.unidata.plaza.UnidataStaffMemberpackage ucar.unidata.plaza; public class UnidataStaffMember { private String name; private Task task; public UnidataStaffMember (String name) { this.name = name; } public Object doTask() throws TaskNotPerformedException { return task.perform(); } public void setTask (Task task) { this.task = task; } }Now the
UnidataStaffMemberonly knows about the tasks through theTaskinterface. Therefore, we can swap out theWriteStatusReportTaskwith another task (e.g.,answerSupportQuestionTask) without having to change the code>UnidataStaffMember code.Wiring the POJOs together with Spring
The missing piece is how the
Taskdependency is given or injected into theUnidataStaffMemberobject. Spring handles that for us via a simple configuration file:unidata.xml<xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd"> <!-- defines a WriteStatusReportTask (can be swapped out with another task at any time) --> <bean id="taskToPerform" class="ucar.unidata.plaza.WriteStatusReportTask"/> <!-- defines a UnidataStaffMember --> <bean id="staffMember" class="ucar.unidata.plaza.UnidataStaffMember"> <!-- inject the constructor value into the constructor --> <constructor-arg value="Jen"/> <!-- inject the task bean into the task property of the UnidataStaffMember --> <property name="task" ref="taskToPerform"/> <bean> <beans>Putting it altogether
When running this application, Spring instantiates our POJOs and injects the required dependencies into the POJOs for us (rather than having our POJOs creating or looking up dependent objects, e.g., new WriteStatusReportTask() and new UnidataStaffMember("jen") are not called since they are Spring-managed objects:
ucar.unidata.plaza.UnidataStaffMemberApplicationpackage ucar.unidata.plaza; import org.springframework.beans.factory.BeanFactory; import org.springframework.beans.factory.xml.XmlBeanFactory; import org.springframework.core.io.FileSystemResource; public class UnidataStaffMemberApplication { public static void main(String[] args) throws Exception { <!-- Use the Spring classes to load the xml config file we specified (above) --> BeanFactory factory = new XmlBeanFactory(new FileSystemResource(unidata.xml)); <!-- get our UnidataStaffMember object (Jen) from the factory --> UnidataStaffMember webDeveloper = (UnidataStaffMember) factory.getBean("staffMember"); <!-- tell our UnidataStaffMember object to perform her task (WriteStatusReportTask) --> webDeveloper.performTask(); } }For web development have the flexibility to configure and construct the major elements of your application via an XML is huge. Application components in the form of Spring-managed beans can be easily swapped out in the XML file without having to change a single line of code. This, coupled with a few other Spring features, such as Spring's Data Access Object (DAO) support and Spring MVC allows for a web application to be put together quickly and easily witha clean separation of tiers.
The modular design to application development using IoC also allows for easy unit testing, hopefully aiding in the detection and correction of more bugs before a release.
Aspect Oriented Programming (AOP)
Another Ah ha! moment for me. In short, Spring AOP allows the POJOs to only be responsible for the business logic for which they were created while keeping the cross-cutting, non-business logic code (e.g., logging, etc.) out of the POJOs. This cross-cutting code is then applied to the POJOs by Spring using an AspectJ-like nomenclature. While AOP in general can have a bit of a learning curve, Spring does its best to make AOP simple.
Additional features
The core Spring framework contains many other useful features not listed above. The Spring project also has additional modules, add-ons and integration tools that can be used in conjunction with Spring. Some of the more notable framework features and add-ons are:
- Effective JDBC and Hibernate data access
- Declarative transaction management
- Spring Web MVC
- Spring Web Flow
- Acegi Security
- Remoting, JMS, and JMX
Spring as a standard?
With the adoption of Spring by Jen and the THREDDS group for the TDS, we are taking a common approach/architecture to our development. The use of standards and conventions to some degree promotes knowledge-sharing, code reuse, peer-review, and better quality of work.
If an application was developed using Spring, certain things are understood: structure, configuration, etc. If someone (e.g., a unidata developer or a user of unidata software) wishes to extend or take over development of a Spring-based app, it wouldn't take him/her much time to spin up on how the application works.
For more information about the Spring framework, visit:
An interesting conversation with John Caron has resulted in Jen installing blogging software on the Unidata website (pebble). Many developers of commercial and opensource software keep blogs to share development ideas, tips, and collect user feedback. Blogging by Unidata developers could providing a unique opportunity to share ideas with the community.
Goals and techniques to maintain a focused discussion via Unidata blogging still needs to be fleshed out. Perhaps the Usercomm, Polcomm, or other members of the community may have ideas and/or a need for contributing to the Unidata blog?
A link to the blog will be published/advertised when posts are being made. Stay tuned.
Some recent changes have been made to the Access Control Rules that govern access to McIDAS based on some concerns about distribution of Unidata McIDAS-X to institutions outside of the United States. Tom and Jen will be working to modify the existing Participation Policy in the Unidata community to address these concerns. As it stands now, website access to McIDAS is governed by the following Access Control Rules:
The user must have provided:
OR
These current ACRs should 'catch' all attempted access to McIDAS by institutions outside of the United States so that they may be approved on a case-by-case basis.
For more information about access to McIDAS, please see the McIDAS status report.
Jeff McWhirter has been developing a Repository for Archiving, Managing and Accessing Diverse DAta (RAMADDA). Jen and Jeff spent some time in creating a servlet wrapper so that RAMADDA could be run as web application within a servlet container (such as Tomcat) in addition to its normal standalone mode. Tomcat 'sandboxes' have been created on both andy (development server) and conan (production server) so that Jeff may continue his development of RAMADDA.
Alas, the mailing list and forum saga is not over. After a year of running in production mode, the current setup is showing its strengths and weaknesses.
Concerns:
Mailman is the probably one of the most popular and widely-used mailing list managers. Out-of-the-box mailman is a easy to use. However, added in customizations and the mailman environment quickly gets complex and unruly.
- Mailman's HTML archives are yucky (a term that has been applied by more than one person). Common complaints are: threading issues; long run-on lines from email clients that 'wrap' paragraph text; archive format issues (not very attractive and shown by date), handling and display of attachments or multi-part content, etc. A separate mailing list archival package (MHonArch) can be integrated with Mailman to allow further customization/control over the appearance of the archives. However, this would involve adding another level of complexity (yet another component) to the mailing list/forum environment. More thought and discussion would need to take place before such a solution was implemented.
- The support archive messages are handled via MHonArch, which provides a different and inconsistent interface. (An argument for incorporating MHonArch with Mailman).
- 'Customization' in mailman often required modification of python code (e.g., integration with our RDBMS. Mailman makes extensive use of pickled files which cannot be cracked and read in a normal manner.
- Certain administrative features cannot easily be applied on a global level, e.g., the display and handling of pending messages for multiple lists.
Similar to mailman, the Jive forums Out-of-the-box are easy to install and use. However, customization of the forum software can quickly lead to complexities that border on the un-maintainable. Worse yet, the actual use of the forums by Unidata staff is no where near the predicted use of the forums (the IDV group is the exception). A lot of $$ and time/effort for customization has gone into the forums - one wonders if it is worth the effort.
Therefore, while it is not a high priority, Jen will continue to investigate and look for other solutions to the forum/mailing list dilemma. Namely, look for lighter-weight fourm packages and mailing list managers that handle customization easier.
![]()
Jen set up an account with Google Analytics and has had it tracking the Unidata website. By registering with the Google Analytics site and adding some JavaScript to our pages (easy with mod_layout), Unidata essentially now has a free, online website analysis package that gives us just as much information as Sawmill, AWStats, etc. (Google's service was modeled upon Urchin Software Corporation's analytics system, Urchin on Demand. Google Analytics runs as a software-as-a-service (SAAS) version of the product.)
The Google Analytics result data can be emailed and exported in a variety of formats. In addition to accessing the information in these formats, Jen has created a user account for Unidata staff to access and query the results directly.
You can do a lot with this, but for a complete list of features, see: Google Analytics Tutorial and visit the Google Analytics site at: http://www.google.com/analytics/indexu.html
One of the cooler features offered by Google Analytics is a Site Overlay of visitor click patterns. The stats are overlay the web page of interest and give the statistics of viewer clicks for each link. This can be a very effective tool in determining how users navigate a site, tracking down usability issues, and revealing the popular vs. un-popular content. See the example screen-capture of the Unidata home page for an example:
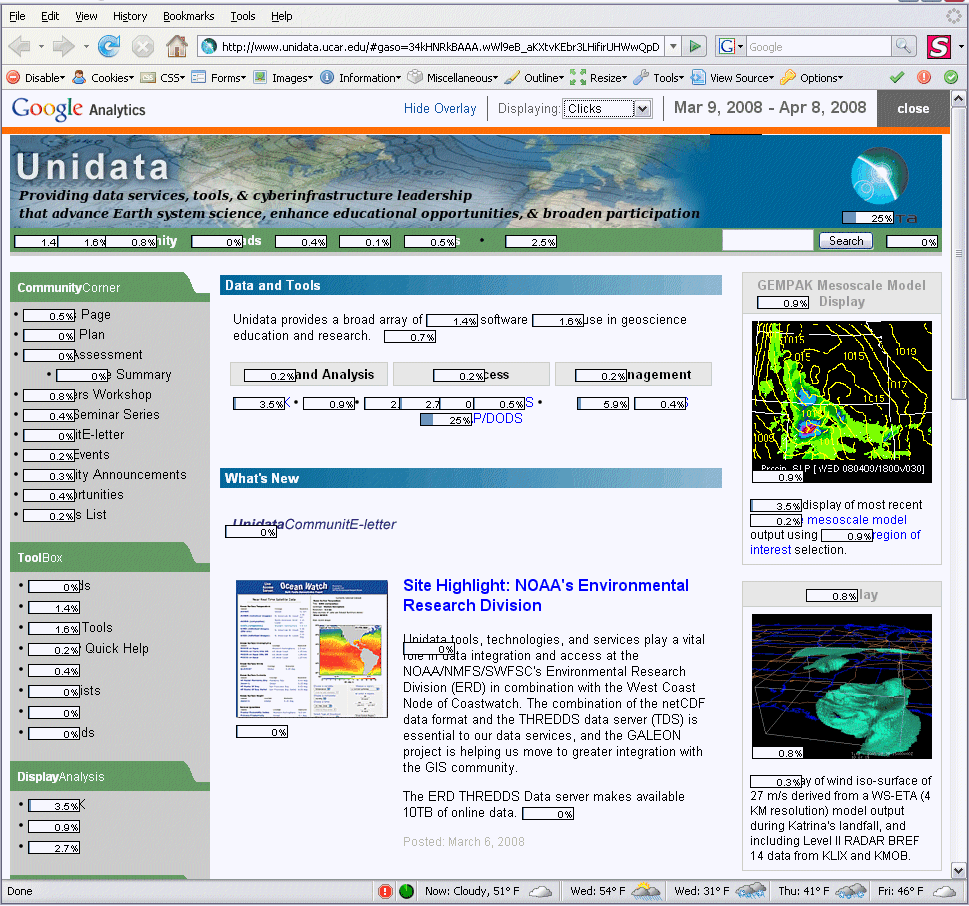
Click to enlarge image
Subsequent Usercomm and Polcomm status reports will contain the following basic Unidata website stats/information for your examination (please let Jen know if you would like to add any additional stat information to this list):