Hi Kevin, Pete, et. al,
On 10/26/21 12:05, Tyle, Kevin R wrote:
> Hi everyone, over the past several days we’ve noticed another big
> degradation of GFS data receipt via CONDUIT. Pete, can you confirm the
> same on your end?
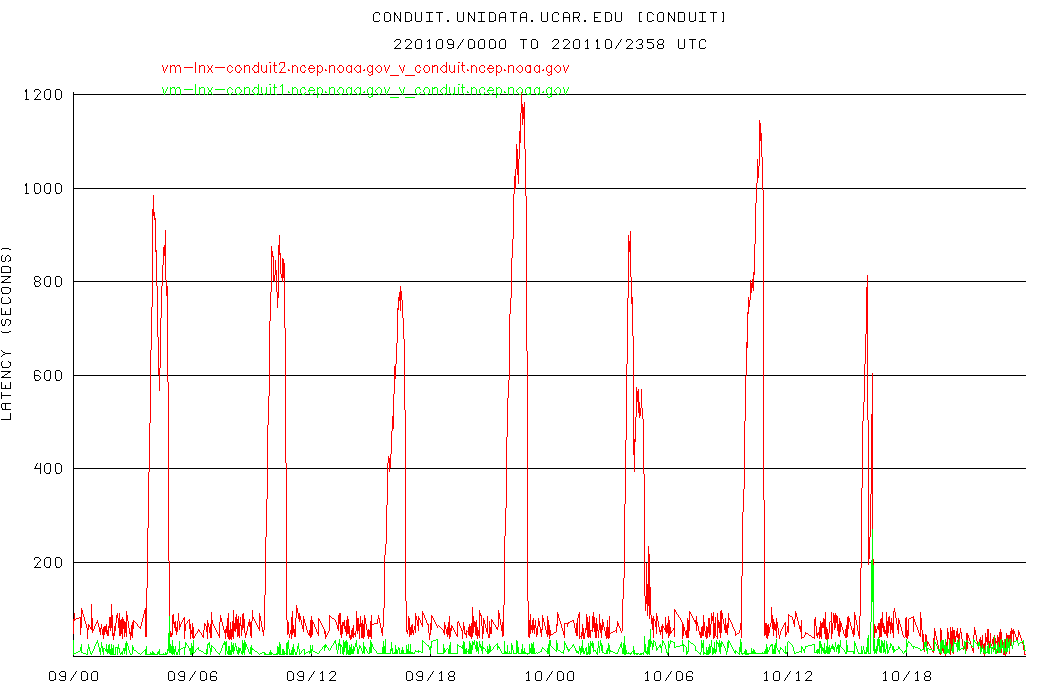
We can confirm that we are seeing the same high latencies as you
are. Here is the CONDUIT latency plot for the machine that we use
to REQUEST CONDUIT from NCEP:
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+conduit.unidata.ucar.edu
During the somewhat recently held LDM virtual training workshop, we
had the opportunity to work with some of the folks that maintain
the top level CONDUIT source machines in NCEP, and we believe that
we identified the cause for the products that are not making it into
the CONDUIT feed - there is not enough memory (RAM) on the virtual
machines to allow for the LDM queue size to be increased enough for
all of the data to be sent during volume peaks. This issue was
discussed during one of the recently held virtual User Committee
meetings, and we were advised that it may not be possible to upgrade/
redo the virtual machines until sometime in 2022. Our NOAA contact
was going to see if something could be done earlier than this, but
we have not heard whether or not this will be possible.
if the memory can not be increased on the NCEP CONDUIT source
machines, the option on the table is to reduce the CONDUIT
content. Since the volume in CONDUIT is _heavily_ dominated by
GFS 0.25 degree data, it would seem that would need to be reduced,
possibly by including fewer forecast hours.
We are not happy with the current situation (a massive understatement),
but we are not in a position to affect the change(s) that are needed
to return CONDUIT to full functionality.
Cheers,
Tom
> _________________________________________________
>
> *From:* conduit <
address@hidden> *On Behalf Of *Pete
> Pokrandt via conduit
> *Sent:* Tuesday, August 31, 2021 12:47 PM
> *To:* Jesse Marks - NOAA Affiliate <
address@hidden>;
address@hidden
> *Cc:* _NWS NCEP NCO Dataflow <
address@hidden>; Anne Myckow - NOAA
> Federal <
address@hidden>;
address@hidden;
>
address@hidden
> *Subject:* Re: [conduit] 20210830: Re: High CONDUIT latencies from
>
vm-lnx-conduit2.ncep.noaa.gov
>
> Thanks for the update, Jesse. I can confirm that we are seeing smaller
> lags originating from conduit2, and since yesterday's 18 UTC run, I
> don't think we have missed any data here at UW-Madison.
>
> Kevin Tyle, how's your reception been at Albany since the 18 UTC run
> yesterday?
>
> Pete
>
> -----
> Pete Pokrandt - Systems Programmer
> UW-Madison Dept of Atmospheric and Oceanic Sciences
> 608-262-3086 -
address@hidden <
mailto:address@hidden>
>
> ------------------------------------------------------------------------
>
> *From:*Jesse Marks - NOAA Affiliate <
address@hidden
> <
mailto:address@hidden>>
> *Sent:* Tuesday, August 31, 2021 10:26 AM
> *To:*
address@hidden <
mailto:address@hidden> <
address@hidden
> <
mailto:address@hidden>>
> *Cc:* Pete Pokrandt <
address@hidden <
mailto:address@hidden>>;
> Anne Myckow - NOAA Federal <
address@hidden
> <
mailto:address@hidden>>;
address@hidden
> <
mailto:address@hidden> <
address@hidden
> <
mailto:address@hidden>>;
address@hidden
> <
mailto:address@hidden>
> <
address@hidden
> <
mailto:address@hidden>>; _NWS NCEP NCO Dataflow
> <
address@hidden <
mailto:address@hidden>>
> *Subject:* Re: 20210830: Re: High CONDUIT latencies from
>
vm-lnx-conduit2.ncep.noaa.gov
>
> Thanks for the quick reply, Tom. Looking through our conduit2 logs, we
> began seeing sends of product from our conduit2 to conduit1 machine
> after we restarted the LDM server on conduit2 yesterday. It appears
> latencies improved fairly significantly at that time:
>
> However we still do not see direct sends from conduit2 to external
> LDMs. Our server team is currently looking into the TCP service issue
> that appears to be causing this problem.
>
> Thanks,
>
> Jesse
>
> On Mon, Aug 30, 2021 at 7:49 PM Tom Yoksas <
address@hidden
> <
mailto:address@hidden>> wrote:
>
> Hi Jesse,
>
> On 8/30/21 5:16 PM, Jesse Marks - NOAA Affiliate wrote:
> > Quick question: how are you computing these latencies?
>
> Latency in the LDM/IDD context is the time difference between when a
> product is first put into an LDM queue for redistribution and the time
> it is received by a downstream machine. This measure of latency, of
> course, requires that the clocks on the originating and receiving
> machines be maintained accurately.
>
> re:
> > More
> > specifically, how do you determine which conduit machine the data is
> > coming from?
>
> The machine on which the product is inserted into the LDM queue is
> available in the LDM transaction. We provide an website where users
> can create graphs of things like feed latencies:
>
> Unidata HomePage
>
https://www.unidata.ucar.edu <
https://www.unidata.ucar.edu>
>
> IDD Operational Status
>
https://rtstats.unidata.ucar.edu/rtstats/
> <
https://rtstats.unidata.ucar.edu/rtstats/>
>
> Real-time IDD Statistics -> Statistics by Host
>
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex>
>
> The variety of measures of feed quality for the Unidata machine that
> is REQUESTing the CNODUIT feed from the NCEP cluster can be found in:
>
>
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu>
>
> The latencies being reported by the Unidata machine that is being fed
> from the NCEP cluster is:
>
> CONDUIT latencies on
conduit.conduit.unidata.ucar.edu
> <
http://conduit.conduit.unidata.ucar.edu>:
>
>
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+conduit.unidata.ucar.edu
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+conduit.unidata.ucar.edu>
>
> As you can see, the traces are color color coded, and the label at the
> top identifies the source machines for products.
>
> re:
> > The reason I ask is because I am not seeing any sends of
> > product from conduit2 in the last several days of logs both to
> our local
> > conduit1 machine and to any distant end users.
>
> Hmm... we are.
>
> re:
> > Also, we have isolated what is likely the issue and will have our
> team
> > take a closer look in the morning. I'm hopeful they'll be able to
> > resolve this soon.
>
> Excellent! We are hopeful that the source of the high latencies will
> be identified and fixed.
>
> Cheers,
>
> Tom
>
> > On Mon, Aug 30, 2021 at 5:24 PM Anne Myckow - NOAA Federal
> > <
address@hidden <
mailto:address@hidden>
> <
mailto:
address@hidden <
mailto:address@hidden>>> wrote:
> >
> > Pete,
> >
> > Random aside, can you please update your doco to say that
> > Dataflow's email list is now
address@hidden
> <
mailto:address@hidden>
> > <
mailto:
address@hidden <
mailto:address@hidden>>
> ? I'm CC'ing it here. That other
> > email address is going to get turned off within the next year.
> >
> > Thanks,
> > Anne
> >
> > On Wed, Aug 18, 2021 at 4:02 PM Pete Pokrandt
> <
address@hidden <
mailto:address@hidden>
> > <
mailto:
address@hidden <
mailto:address@hidden>>> wrote:
> >
> > Dear Anne, Dustin and all,
> >
> > Recently we have noticed fairly high latencies on the CONDUIT
> > ldm data feed originating from the machine
> >
vm-lnx-conduit2.ncep.noaa.gov <
http://vm-lnx-conduit2.ncep.noaa.gov>
> > <
http://vm-lnx-conduit2.ncep.noaa.gov
> <
http://vm-lnx-conduit2.ncep.noaa.gov>>. The feed originating
> > from
vm-lnx-conduit1.ncep.noaa.gov
> <
http://vm-lnx-conduit1.ncep.noaa.gov>
> > <
http://vm-lnx-conduit1.ncep.noaa.gov
> <
http://vm-lnx-conduit1.ncep.noaa.gov>> does not have the high
> > latencies. Unidata and other top level feeds are seeing
> similar
> > high latencies from
vm-lnx-conduit2.ncep.noaa.gov
> <
http://vm-lnx-conduit2.ncep.noaa.gov>
> > <
http://vm-lnx-conduit2.ncep.noaa.gov
> <
http://vm-lnx-conduit2.ncep.noaa.gov>>.
> >
> > Here are some graphs showing the latencies that I'm seeing:
> >
> > From
> >
>
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu>
> >
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu>> -
> > latencies for CONDUIT data arriving at our UW-Madison AOS
> ingest
> > machine
> >
> >
> >
> > From
> >
>
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu>
> >
> <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu <
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu>> (latencies
> > at Unidata)
> >
> >
> >
> > At least here at UW-Madison, these latencies are causing
> us to
> > lose some data during the large GFS/GEFS periods.
> >
> > Any idea what might be causing this?
> >
> > Pete
> >
> >
> >
> >
> >
> <
http://www.weather.com/tv/shows/wx-geeks/video/the-incredible-shrinking-cold-pool <
http://www.weather.com/tv/shows/wx-geeks/video/the-incredible-shrinking-cold-pool>>-----
> > Pete Pokrandt - Systems Programmer
> > UW-Madison Dept of Atmospheric and Oceanic Sciences
> > 608-262-3086 -
address@hidden
> <
mailto:address@hidden> <
mailto:
address@hidden
> <
mailto:address@hidden>>
> >
> >
> >
> > --
> > Anne Myckow
> > Dataflow Team Lead
> > NWS/NCEP/NCO
> >
> >
> >
> > --
> > Jesse Marks
> > Dataflow Analyst
> > NCEP Central Operations
> > 678-896-9420
>
> --
> +----------------------------------------------------------------------+
> * Tom Yoksas UCAR Unidata Program *
> * (303) 497-8642 (last resort) P.O. Box 3000 *
> *
address@hidden <
mailto:address@hidden>
> Boulder, CO 80307 *
> * Unidata WWW Service
http://www.unidata.ucar.edu/
> <
http://www.unidata.ucar.edu/> *
> +----------------------------------------------------------------------+
>
>
>
> --
>
> Jesse Marks
>
> Dataflow Analyst
>
> NCEP Central Operations
>
> 678-896-9420
>
--
+----------------------------------------------------------------------+
* Tom Yoksas UCAR Unidata Program *
* (303) 497-8642 (last resort) P.O. Box 3000 *
*
address@hidden Boulder, CO 80307 *
* Unidata WWW Service
http://www.unidata.ucar.edu/ *
+----------------------------------------------------------------------+