Hi Antonio, thanks for the suggestions.
The latest or proxy dataset feature would be very helpful. However, I've
set it up but it creates a 'latest' catalog for each nested folder (see
screenshot attached). Is it possible to have it at the top level of the
filesystem catalog?
Here's how I inserted it in the catalog.xml:
<service name="latest" serviceType="Resolver" base="" />
<datasetScan name="WRF" ID="testWRF"
path="WRF" location="content/testdata/wrfdata">
<addProxies>
<latestComplete name="latestComplete.xml" top="true"
serviceName="latest" lastModifiedLimit=""""""""60000" />
</addProxies>
<metadata inherited="true">
....
</metadata>
</datasetScan>
My filesystem has this strucuture:
WRF/2018/01012018/file.nc
"/file2.nc
"/file3.nc
WRF/2018/01022018/file.nc
"/file2.nc
"/file3.nc
Every day a new folder will appear. I would set up a harvester that looks
at the new folder, but I can't modify the name. Geonetwork will harvest
from a specific xml catalog which has a fixed name. Is it possible to
gather all 'latest' files in a catalog at the upper level (ex.
WRF/2018/latest.xml)?
Many thanks,
Chiara
On 5 July 2018 at 19:55, Antonio S. Cofiño <cofinoa@xxxxxxxxx> wrote:
> Hi Chiara,
> On 05/07/18 08:54, Chiara Scaini wrote:
>
> Hi Antonio and thanks for answering. I'm using the version 4.6.11.
>
> Here's an example of 2 folders of the Filesystem containing data from 2
> different models. I'm currently creating 2 different datasetScan so data
> are located in different folders in my thredds catalog.
>
> /filesystem/operative/data/wrfop/outputs/2018
> /filesystem/operative/data//ariareg/farm/air_quality_forecast/2018
>
> Each folder contains several daily folders with files that I can filter by
> name, (ex. <include wildcard="*myfile_*"/>)
> /filesystem/operative/data//ariareg/farm/air_quality_
> forecast/2018/20180620_00/myfile.nc
>
> But my aim is to harvest data from Thredds to Geonetwork only once per
> file. Since Geonetwork can account for the 'harvest' attribute, I would
> like to *set the harvest attribute to 'false' for all data but the newly
> created*. Do you think that's possible with the current functions?
>
> I don't have experience with GeoNetwork, but looking it's documentation
> what you want its to harvest thredds catalogs *from* GeoNetwork. From my
> POV the "problem" is that GeoNetwork it's harvesting datasets (atomic or
> collections) that were already harvested and you don' want to do it again .
> In fact, in the GeoNetwork example for harvesting a remote thredds catalog,
> they it is ignoring the "harvest" attribute of the dataset. It may be it's
> beyoond of my knowledge but it would very easy for GeoNetwork, to "cache"
> already harvested metadata based on the ID attribute of the thredds
> datasets (collections and atomic ones). The harvest attribute it's only
> applied to the root of the datasetScan collection and it's not inherent
> because it's not a metadata element.
>
>
>
> A workaround would be to create a temporary folder (and catalog) to be
> used for harvesting. A crontab job is creating the new data in the
> filesystem everyday and it cancreate the link too. The catalog would
> contain symbolic links and the attribute "harvest=true". The links would be
> deleted and replaced daily from crontab. Once imported to Geonetwork, I
> would of course modify the thredds links to point to the main catalog and
> not to a 404.
>
> That could be a solution, like the latest dataset in:
> http://motherlode.ucar.edu/thredds/catalog/satellite/3.9/
> WEST-CONUS_4km/catalog.html
>
> It May be you could use the latest or proxy dataset feature described in
> [1]. This allows to generate a proxy dataset wich points to latest "added"
> dataset and provided the URL to the latest dataset to the GeoNetwork
> harvester. I'm not sure if this solves your issue, but it worth it the try.
> This an example:
> http://motherlode.ucar.edu/thredds/catalog/nws/metar/
> ncdecoded/files/catalog.html
>
> The other option could be to "regenerate" the catalogs dynamically and
> trigger a catalog reload to the TDS instance. This quite similar to your
> option, but more dynamic although require more mchinery to complete.
>
> Here's what i got so far with the 'harvest' attribute set at the
> datasetScan level. I did what you suggested about the filter:
> <filter>
> <include wildcard="*wrfout_*"/>
> </filter>
> <filter>
> <include collection="true"/>
> </filter>
> <filter>
> <include atomic="true"/>
> </filter>
>
> The harvest attribute is not set for the inner dataset nodes, but only for
> the dataset parent. Is that what I should expect?
>
> Yes, the harvest it's only for the parent collection dataset.
>
>
> <catalog version="1.0.1"><service name="all" serviceType="Compound"
> base=""><service name="odap" serviceType="OPENDAP"
> base="/thredds/dodsC/"/><service
> name="http" serviceType="HTTPServer" base="/thredds/fileServer/"/><service
> name="wms" serviceType="WMS" base="/thredds/wms/"/><service name="ncss"
> serviceType="NetcdfSubset" base="/thredds/ncss/"/></service><dataset
> name="AUXILIARY" harvest="true" ID="testAUXILIARY"><metadata
> inherited="true"><serviceName>all</serviceName><dataType>GRID</dataType><documentation
> type="summary">This is a summary for my test ARPA catalog for WRF runs.
> Runs are made at 12Z and 00Z, with analysis an d forecasts every 6 hours
> out to 60 hours. Horizontal = 93 by 65 points, resolution 81.27 km,
> LambertConformal projection. Vertical = 1000 to 100 hPa pressure
> levels.</documentation><keyword>WRF outputs</keyword><geospatialCoverage><
> northsouth><start>25.0</start><size>35.0</size><units>
> degrees_north</units></northsouth><eastwest><start>-
> 20.0</start><size>50.0</size><units>degrees_east</units></
> eastwest><updown><start>0.0</start><size>0.0</size><units>
> km</units></updown></geospatialCoverage><timeCoverage><end>present</end><duration>5
> years</duration></timeCoverage><variables vocabulary="GRIB-1"/><variables
> vocabulary=""><variable name="Z_sfc" vocabulary_name="Geopotential H"
> units="gp m">Geopotential height,
> gpm</variable></variables></metadata><dataset
> name="wrfout_d03_test7" ID="testAUXILIARY/wrfout_d03_test7"
> urlPath="AUXILIARY/wrfout_d03_test7"><dataSize
> units="Mbytes">137.2</dataSize><date
> type="modified">2018-06-28T10:19:28Z</date></dataset><dataset
> name="wrfout_d03_test6" ID="testAUXILIARY/wrfout_d03_test6"
> urlPath="AUXILIARY/wrfout_d03_test6"><dataSize
> units="Mbytes">137.2</dataSize><date
> type="modified">2018-06-28T10:19:28Z</date></dataset></dataset></catalog>
>
> Thanks for your time,
> Chiara
>
>
> Hope this helps
>
> Regards
>
> Antonio
>
> [1] https://www.unidata.ucar.edu/software/thredds/current/tds/
> reference/DatasetScan.html#Adding_Proxy_Datasets
>
>
>
> On 4 July 2018 at 19:46, Antonio S. Cofiño <cofinoa@xxxxxxxxx> wrote:
>
>> Hi Chiara,
>>
>> I'm answering inline.
>>
>>
>>
>> On 04/07/18 18:23, Chiara Scaini wrote:
>>
>> Hi all, I'm setting up a geospatial data and metadata portal based on
>> thredds catalog and the Geonetwork engine and web application. I am working
>> on Linux CentOS and my applications are deployed with Tomcat8.
>>
>> Which TDS version are you using?
>>
>> I am populating a thredds catalog based on a filesystem containing
>> meteorological data. Geonetwork then harvests the catalog and populates the
>> application. However, and given that I'm updating the data on the web side,
>> I would like to harvest only once the data.
>>
>> I tried to set the 'harvest' attribute from the catalog, but without
>> success. Here's an excerpt of my catalog.xml file:
>>
>> The "harvest" it's been only defined as attribute for dataset (and
>> datasetScan) elements, but IMO it's no the purpose you are looking for (see
>> [1])
>>
>>
>> <datasetScan name="AUXILIARY" ID="testAUXILIARY"
>> path="AUXILIARY" location="content/testdata/auxiliary-aux"
>> harvest="true">
>>
>> This harvest is correct.
>>
>> <metadata inherited="true">
>> <serviceName>all</serviceName>
>> <dataType>Grid</dataType>
>> <dataFormatType>NetCDF</dataFormatType>
>> <DatasetType harvest="true"></DatasetType>
>> <harvest>true</harvest>
>>
>> This hrvest it's not defined in the THREDDS Client Catalog Specification
>> (see [1])
>>
>> <keyword>WRF outputs</keyword>
>> <documentation type="summary">This is a summary for my test ARPA
>> catalog for WRF runs. Runs are made at 12Z and 00Z, with analysis an
>> d forecasts every 6 hours out to 60 hours. Horizontal = 93 by 65
>> points, resolution 81.27 km, LambertConformal projection. Vertical = 1000 to
>> 100 hPa pressure levels.</documentation>
>> <timeCoverage>
>> <end>present</end>
>> <duration>5 years</duration>
>> </timeCoverage>
>> <variables vocabulary="GRIB-1" />
>> <variables vocabulary="">
>> <variable name="Z_sfc" vocabulary_name="Geopotential H"
>> units="gp m">Geopotential height, gpm</variable>
>> </variables>
>> </metadata>
>>
>> <filter>
>> <include wildcard="*wrfout_*"/>
>> </filter>
>>
>> How files are distributed on disk? they are under directories? If yes the
>> you need to add a include filter with the collection attribute="true" (see
>> [2] and [3])
>>
>>
>>
>> <addDatasetSize/>
>> <addTimeCoverage datasetNameMatchPattern="([0-9
>> ]{2})_([0-9]{4})-([0-9]{2})-([0-9]{2})_([0-9]{2}):([0-9]{2}):([0-9]{2})"
>> startTimeSubstitutionPattern="$2-$3-$4T$5:00:00"
>> duration="6 hours" />
>>
>> <namer>
>> <regExpOnName regExp="([0-9]{4})([0-9]{2})([0-9]{2})_([0-9]{2})"
>> replaceString="WRF $1-$2-$3T$4:00:00" />
>> <regExpOnName regExp="([0-9]{2})_([0-9]{4})-
>> ([0-9]{2})-([0-9]{2})_([0-9]{2}):([0-9]{2}):([0-9]{2})"
>> replaceString="WRF Domain-$1 $2-$3-$4T$5:00:00" />
>> </namer>
>>
>> </datasetScan>
>>
>>
>> Even if I set the harvest="true" attribute, it is not inherited by the
>> datasets and thus the harvester does not get the files. I can also ignore
>> the 'harvest' attribute while harvesting, but my aim is to harvest only new
>> files using an auxiliary catalog that contains symbolic links (and updating
>> the Thredds path after harvesting).
>>
>> Am I missing something? How would you sistematically add the harvest
>> attribute to all inner datasets in a nested filesystem? Or, would it make
>> sense to create two catalogs using the time filter options (ex. all up to
>> yesterday in one catalog, and today's files in another)? Can you show me an
>> example of usage of those filters in a datasetScan?
>>
>> Many thanks,
>> Chiara
>>
>>
>> How this helps
>> Regards
>>
>> Antonio
>>
>>
>> [1] https://www.unidata.ucar.edu/software/thredds/current/tds/ca
>> talog/InvCatalogSpec.html#dataset
>> [2] https://www.unidata.ucar.edu/software/thredds/current/tds/ca
>> talog/InvCatalogServerSpec.html#datasetScan_Element#filter_Element
>> [3] https://www.unidata.ucar.edu/software/thredds/current/tds/re
>> ference/DatasetScan.html#Including_Only_the_Desired_Files
>>
>> --
>> Antonio S. Cofiño
>> Dep. de Matemática Aplicada y
>> Ciencias de la Computación
>> Universidad de Cantabriahttp://www.meteo.unican.es
>>
>>
>>
>> --
>> Chiara Scaini
>>
>>
>> _______________________________________________
>> NOTE: All exchanges posted to Unidata maintained email lists are
>> recorded in the Unidata inquiry tracking system and made publicly
>> available through the web. Users who post to any of the lists we
>> maintain are reminded to remove any personal information that they
>> do not want to be made public.
>>
>>
>> thredds mailing listthredds@xxxxxxxxxxxxxxxx
>> For list information or to unsubscribe, visit:
>> http://www.unidata.ucar.edu/mailing_lists/
>>
>>
>>
>
>
> --
> Chiara Scaini
>
>
>
--
Chiara Scaini
Attachment:
thredds.png
Description: PNG image
thredds archives: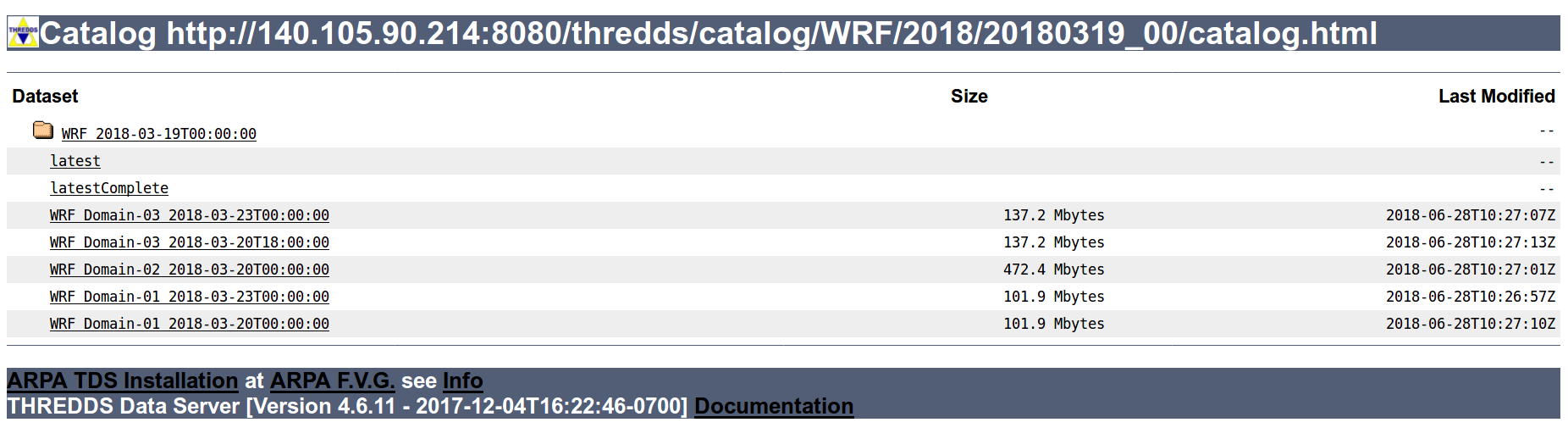{kind=link}