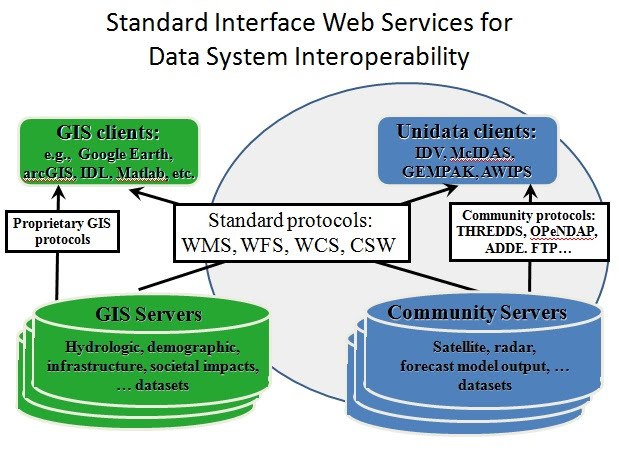
General concepts
The overall objective is simple: make it possible for authors
to create online publications that enable readers to access, analyze,
and display the data discussed in the publication.
Currently available (formal and community) standard web services
have made it possible to create rudimentary examples of such data
interactive documents with the following characteristics:
- Straightforward HTML documents can be created on public wiki or local web server.
- Via embedded links, reader accesses
- the usual textual information in a publication
- data
- processes for analyzing data
- display tools.
- Tools can be:
- thin web clients,
- rich desktop applications.
Image from Presentation Slide Shows Multiple Data Interaction Modes
(Note that the reader has access to the data and control over the analysis and display.)
From within the document, reader can interact with data via:
- data cited in the publication plus a host of related datasets
- analysis tools,
- “live” tables
- downloads.
Simple examples of such documents are available now:
Thoughts and questions relating to the possibility of data interactive publications
- Publications are the "coin of the realm" -- the highest-valued metric of the academic community
- Data citation (for transparency, reproducibility, etc.) is an emerging issue for scientific publications
- Data access and analysis are the basis of nearly all those publications
- In the present technological environment, can we bridge the gap between the publications and the data analysis?
- In the era of big data, having data and processing on same system increases scalability.
- Will this work in an era of server side (cloud?) web processing services and mobile client devices?
Advantages
- Convenient authoring of online publications that enable the reader to access and analyze the data cited in the publication
- Community Incentive: makes “documentation” of data a rewarded part of an academic’s job
- Transparency: fosters openness by providing broader and easier access to processing and data as well as products
- Search: data interactive publications can be found via Google which in turn:
- leads the searcher to the datasets and analysis tools the publication points to
- makes it possible to do Google-type rankings based on pointers into and out of the documents and datasets
- Server flexibility: services can be on local workstation/cluster, on central server, in the cloud, or in Wyoming
- Scalability: processing can be performed near “big data” stores
- Collaboration: could foster more NCAR/Unidata collaboration
- Internal Cooperation: would involve both engineering and non-engineering staff within Unidata
- Client flexibility: data analysis can be driven from mobile devices as well as desktop
Challenges
- New way of thinking for developers and users
- Additional effort: "skunk works," new or re-programmed staff
- Persistence of all components: datasets, processing services, and interfaces
- Computing resources: distribution and limitations
- Security: authentication and authorization
- Primitive web processing services at present
- Interfaces are new and generally untried in an environment where people are relying on them
- Need to engage publications industry
Implications of Recent Developments
Earlier barriers are being overcome:
- Browser-based access to interactivity is becoming more common (Live Access Server, TDS/WMS/GODIVA, ERDDAP, FerretTDS…)
- Does it make sense to consider putting some IDV analysis functionality on the server side to create a sort of IDV/TDS)?
- Server-side (on a departmental server or in the cloud?) processing is a viable platform for interactivity
- RAMADDA/TDS provides mechanism for persistent storage of datasets by user community
- Clients with modest processing/storage ability come into play (tablets, smart phones)
- Documents, data, storage, data access, processing capabilities, user devices can all be distributed
- Processing can be co-located with large datasets.
A Few of the Collaborating Organizations
- NOAA (e.g., PMEL, PFEL, NCDC, NGDC, NCPP, IOOS)
- NASA
- USGS
- OGC (Open Geospatial Consortium)
- CF (Climate and Forecast) Community
- CUAHSI (Hydrology)
- NCAR (GIS Program, CISL, …)
- NEON (National Ecological Observatory Network) Data Services
- International (Italian National Research Council, British
Atmospheric Data Center, University of Reading E-science Center, Meteo
France, Jacobs University of Bremen, British Met Office, Australian
Bureau of Meteorology, …)
- Industry (ESRI, ITTvis, Applied Science Associates, …)
Unidata Outreach to Other Communities
This recent revival of the concept of data interactive documents
seemed to flow naturally out of the Unidata outreach efforts to make
atmospheric data available to interested parties outside the
meteorological discipline. The initial implementation of standard
interfaces for data access led to consideration of the use of web
processing services in addition to the simple data access services. This
opens up a wide range of options for where analysis and display
functions get done.
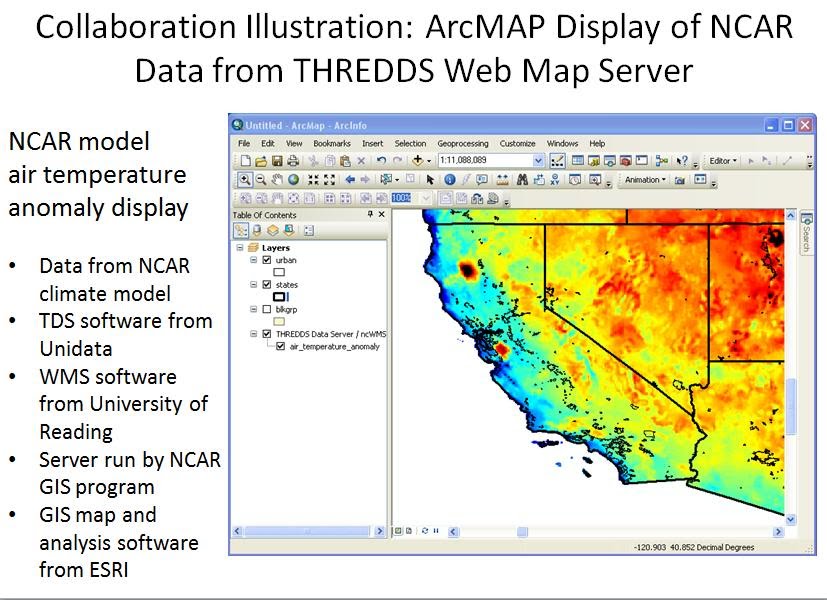
Unidata's main focus in on
service to the US synoptic and mesoscale meteorology academic community.
For that groups of researchers and educators, Unidata provides a
full suite of end to end products shown on the right side of the the
diagram below. In many ways it is a tailored and valuable
"stovepipe" of real-time push and pull data service, decoders, web
services, and desktop applications that have served the core community
well for decades. However, it is important for the Unidata
Program Center to also make the data available in a reasonably
convenient form to other communities such as the GIS realm. This
is done by providing infrastructure that includes standard interfaces
such as those of the OGC (Web Map Service, Web Coverage Service, Catalog
Service for the Web, etc.). Then any client software that
supports these standard interfaces can access data from Unidata servers.
 There
is now an increasing emphasis on Web Processing Services in addtion to
the traditional data access services. When combined with
browser-based analysis and display capabilities, new possibilities open
up as show in the diagram below.
The
addition of processing functions on the server side and lightweight,
browser- or app-based applications on the client side opens up a wide
spectrum of options for distributing the load between clients and
servers. On the server side, one can envision everything from a
THREDDS Data Server running on a departmental server augmented with
processing power and functionality to a set of processing functions
running in a commercial cloud service. Closer to home, there is
the possibility of controling heavyweight big-iron numerical
computations on the powerful system being installed by NCAR in Wyoming.
For clients, the current desktop applications will always be
valuable and some may even be ported to run on small mobile devices.
But one can also envisions situations where it might be better to
have simple control and display functions on a smartphone with the bulk
of the computational load being performed elsewhere.
There
are already examples in the community of the transfer of processing
functions from the desktop to the server side. Both Ferret and
GRaDS started out as desktop applications, but there now exist
Ferret/TDS and GRaDS/DODS servers available which can perform most of
the destop analysis and display functions on the server. In fact,
the Live Access Server is in effect a browser-based interface to the
Ferret/TDS functionality. Likewise, the GODIVA web-interface has
been built on top of the WMS interface from the University of Reading
that is now part of the TDS distribution.
There
are two key points to note. One is that the use of standard
interfaces greatly facilitates the integration of software components
that were not, ab initio, designed to work together specifically.
A related point is that the software development work is shared
among disparate organizations ranging from NOAA labs to NASA groups to
the University of Reading to Unidata. In some sense we have a
mechanism that fosters interoperability among data systems, processing
systems, and organizations.
Areas Needing Attention/Resources
- TDS/RAMADDA authentication enabling user data input for persistent storage
- Web processing services that enable more processing on server side (cloud?)
- Simple apps on modest client platforms that enable interaction with data access AND PROCESSING services
References
|
Attachments (11)
-
ERDDAPsite.jpg - on Jun 1, 2011 8:46 AM by Ben Domenico (version 1)
332k
View Download
-
GFS Temperature in GODIVA2.jpg - on Jun 1, 2011 8:48 AM by Ben Domenico (version 1)
263k
View Download
-
GoogleWikiPublication.jpg - on Jun 1, 2011 8:48 AM by Ben Domenico (version 1)
215k
View Download
-
IDV Visualization.jpg - on Jun 1, 2011 8:48 AM by Ben Domenico (version 1)
216k
View Download
-
LAS CO2 Flux.jpg - on Jun 1, 2011 8:49 AM by Ben Domenico (version 1)
80k
View Download
-
MultipleInteractionsWithText.jpg - on Jun 1, 2011 8:42 AM by Ben Domenico (version 1)
118k
View Download
-
NASAgiovanniSST.jpg - on Jun 1, 2011 8:49 AM by Ben Domenico (version 1)
141k
View Download
-
Publication & Interactions.jpg - on Jun 1, 2011 8:51 AM by Ben Domenico (version 1)
607k
View Download
-
StandardInterfacesForOutreach.jpg - on Jun 1, 2011 11:47 AM by Ben Domenico (version 1)
105k
View Download
-
WMS_ArcMap.png - on Jun 1, 2011 8:51 AM by Ben Domenico (version 1)
179k
View Download
-
WebProcessingServicesAdded.jpg - on Jun 1, 2011 12:12 PM by Ben Domenico (version 2 / earlier versions)
80k
View Download
|



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_text_